系列导读:本系列共三篇文章,渐进式地探讨 Stable Diffusion XL(SDXL)模型的推理优化。第一篇聚焦于问题背景与性能剖析,第二篇展开全面的单项优化实践,本篇(终篇)进行混合组合优化与吞吐工程部署。
在前两篇中,我们完成了 SDXL 推理的性能 Profiling 和逐项优化实践。每种单项优化都有其收益上限,而实际工程中往往需要 将多种优化叠加组合 才能逼近性能极限。更进一步,生产部署不仅关注单次延时,更关注 单卡吞吐量(image/s)——这需要从 Batch 策略、多实例部署、GPU 资源调度等系统层面进行优化。
本篇将回答两个核心问题:
- 哪些优化可以叠加?叠加后的实际效果如何?
- 如何最大化单卡吞吐?Batch、多实例、MPS 分别适合什么场景?
实验环境:NVIDIA L20, CUDA 12.x, PyTorch 2.x, 分辨率 1024×1024, 20 步(与生产环境一致)。 Baseline:FP16, 20 步, 单张推理延时 3.9s, 吞吐 0.256 image/s。
1. 混合优化组合实践
1.1 组合策略设计
并非所有优化都能自由叠加。根据第二篇的分析,各优化作用于 Pipeline 的不同层级:
组合兼容性矩阵
═══════════════════════════════════════════════════════════
torch.compile StableFast OneDiff TensorRT
VAE FP16 Fix ✅ ✅ ✅ ✅
Tiny VAE ✅ ✅ ✅ ✅
禁用 CFG ✅ ✅ ✅ ✅
DeepCache ✅ ⚠️ ⚠️ ❌
⚠️ = 部分兼容,需要额外适配
❌ = 不兼容或收益冲突
═══════════════════════════════════════════════════════════
组合原则:
- 编译优化互斥:torch.compile / Stable Fast / OneDiff / TensorRT 只能选其一
- 组件优化可叠加:VAE 替换、CFG 策略、缓存策略之间互不冲突
- 编译 + 组件可以叠加:编译优化加速 UNet Kernel,组件优化减少 VAE 开销或去噪次数,作用于不同环节
基于此,我们设计了以下组合实验方案:
方案 A(精度无损): 编译优化 + VAE 优化
方案 B(轻微有损): 编译优化 + VAE 优化 + 禁用 CFG
方案 C(量化有损): TensorRT + VAE 优化 + INT8 量化
1.2 方案 A:精度无损组合
OneDiff + Tiny VAE
from onediff.infer_compiler import oneflow_compile
from diffusers import AutoencoderTiny, StableDiffusionXLPipeline
vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16)
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae, torch_dtype=torch.float16, variant="fp16"
).to("cuda")
pipe.unet = oneflow_compile(pipe.unet)
| 方法 | 步长 | 延时(s) | 吞吐(image/s) | 显存(GB) | 加速比 |
|---|---|---|---|---|---|
| Base (FP16) | 20 | 3.9 | 0.256 | 11.24 | 1× |
| OneDiff + Tiny VAE | 20 | 3.1 | 0.322 | 6.92 | 1.26× |
TensorRT + VAE FP16 Fix
# TensorRT 引擎构建后,替换 VAE 为 FP16 修复版本
from diffusers import AutoencoderKL
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
# TensorRT pipeline with custom VAE
| 方法 | 步长 | 延时(s) | 吞吐(image/s) | 显存 | 加速比 |
|---|---|---|---|---|---|
| Base (FP16) | 20 | 3.9 | 0.256 | 11.24 GB | 1× |
| TensorRT + VAE FP16 Fix | 20 | 2.75 | 0.363 | — | 1.41× |
分析:TensorRT 组合方案延时降至 2.75s,是无损方案中表现最好的。但需注意 TensorRT 的灵活性限制。
1.3 方案 B:轻微有损组合
在方案 A 的基础上叠加 部分禁用 CFG,进一步压缩延时。
Stable Fast + Tiny VAE + CFG
| 方法 | 步长 | 延时(s) | 吞吐(image/s) | 显存(GB) | 加速比 |
|---|---|---|---|---|---|
| Base (FP16) | 20 | 3.9 | 0.256 | 11.24 | 1× |
| StableFast + Tiny VAE + CFG 75% | 20 | 3.0 | 0.333 | 7.36 | 1.30× |
| StableFast + Tiny VAE + CFG 50% | 20 | 2.7 | 0.370 | 7.36 | 1.44× |
OneDiff + Tiny VAE + CFG
| 方法 | 步长 | 延时(s) | 吞吐(image/s) | 显存(GB) | 加速比 |
|---|---|---|---|---|---|
| Base (FP16) | 20 | 3.9 | 0.256 | 11.24 | 1× |
| OneDiff + Tiny VAE + CFG 75% | 20 | 2.9 | 0.344 | 6.92 | 1.34× |
| OneDiff + Tiny VAE + CFG 50% | 20 | 2.6 | 0.384 | 6.92 | 1.50× |
图片质量对比(OneDiff + Tiny VAE + CFG):
| Base | CFG 75% | CFG 50% |
|---|---|---|
 |  |  |
 |  |  |
CFG 75% 方案图片质量与 Baseline 差异极小;CFG 50% 可感知到细节变化,但整体构图一致。
1.4 方案 C:量化加速组合
TensorRT + Tiny VAE + UNet INT8
TensorRT 支持 INT8 量化推理,通过将 UNet 权重量化为 8 bit 整数,进一步压缩计算量和显存带宽需求。
量化原理:
FP16 权重 (16 bit) → INT8 量化 (8 bit)
├── 计算吞吐量理论翻倍
├── 显存带宽需求减半
└── 但需要校准数据集(Calibration)确保精度
| 方法 | 步长 | 延时(s) | 吞吐(image/s) | 加速比 |
|---|---|---|---|---|
| Base (FP16) | 20 | 3.9 | 0.256 | 1× |
| TensorRT + Tiny VAE + UNet INT8 | 20 | 1.85 | 0.540 | 2.1× |
图片质量对比:
| Base(FP16) | + Tiny VAE | + UNet INT8 |
|---|---|---|
 |  |  |
分析:
- 延时降至 1.85s,是目前所有组合方案中 最快的单张推理速度
- INT8 量化对图片质量有可感知的影响,尤其是细节纹理和颜色过渡
- INT8 量化与 LoRA 的兼容性存在限制:量化后的引擎难以动态加载 LoRA 权重
1.5 混合优化总览
| 方案 | 延时(s) | 吞吐(image/s) | 质量 | 备注 |
|---|---|---|---|---|
| 精度无损 | ||||
| OneDiff + Tiny VAE | 3.1 | 0.322 | 无损 | 灵活,适配性好 |
| TensorRT + VAE FP16 Fix | 2.75 | 0.363 | 无损 | 无损方案最佳 |
| 轻微有损 | ||||
| StableFast + Tiny VAE + CFG 75% | 3.0 | 0.333 | 细微差别 | CFG 稳定性因 prompt 而异 |
| OneDiff + Tiny VAE + CFG 75% | 2.9 | 0.344 | 细微差别 | 同上 |
| OneDiff + Tiny VAE + CFG 50% | 2.6 | 0.384 | 轻微有损 | 质量风险较高 |
| 量化有损 | ||||
| TensorRT + Tiny VAE + INT8 | 1.85 | 0.540 | 有损 | LoRA 兼容性差 |
延时排行(从快到慢):
TRT+TinyVAE+INT8 ███████████░░░░░░░░░ 1.85s (2.1×)
OneDiff+Tiny+CFG50 ██████████████░░░░░░ 2.6s (1.5×)
TRT+VAE FP16 Fix ██████████████░░░░░░ 2.75s (1.41×)
OneDiff+Tiny+CFG75 ███████████████░░░░░ 2.9s (1.34×)
SF+Tiny+CFG75 ███████████████░░░░░ 3.0s (1.30×)
OneDiff+TinyVAE ████████████████░░░░ 3.1s (1.26×)
Baseline (FP16) ████████████████████ 3.9s (1×)
2. 吞吐优化:Batch vs 多实例 vs MPS
单张推理延时的优化存在物理上限。当我们将视角从"单张更快"转向"单位时间出更多图",就进入了吞吐优化的范畴。本节深入对比三种吞吐提升策略。
2.1 三种策略的本质差异
策略 1: Batch 推理
┌─────────────────────────────────┐
│ GPU │
│ ┌───────────────────────────┐ │
│ │ Model (1份) │ │
│ │ Input: [img1, img2, ...] │ │
│ └───────────────────────────┘ │
└─────────────────────────────────┘
→ 多个输入拼接为一个大 batch,一次推理
策略 2: 多实例(Multi-Instance)
┌─────────────────────────────────┐
│ GPU │
│ ┌────────────┐ ┌────────────┐ │
│ │ Model A │ │ Model B │ │
│ │ Input: img1│ │ Input: img2│ │
│ └────────────┘ └────────────┘ │
└─────────────────────────────────┘
→ 多个独立进程,各自加载模型,独立推理
策略 3: 多实例 + MPS
┌─────────────────────────────────┐
│ GPU (MPS Server) │
│ ┌────────────┐ ┌────────────┐ │
│ │ Model A │ │ Model B │ │
│ │ (50% SM) │ │ (50% SM) │ │
│ └────────────┘ └────────────┘ │
└─────────────────────────────────┘
→ 多实例 + MPS 实现真正的 Kernel 并行
| 维度 | Batch | 多实例 | 多实例 + MPS |
|---|---|---|---|
| 模型份数 | 1 份 | N 份 | N 份 |
| 显存开销 | 低(共享权重) | 高(N 倍权重) | 高(N 倍权重) |
| 计算量 | 与 N 张独立推理相同 | 与 N 张独立推理相同 | 同左 |
| 加速原理 | 大矩阵 GEMM 效率更高 | 多进程提高 GPU 利用率 | 真正并行执行 Kernel |
| 灵活性 | 低(参数必须一致) | 高(各实例独立) | 高 |
| 适用场景 | 高并发、统一参数 | 低并发、异构请求 | 低并发、异构请求 |
2.2 Batch 推理实测
Batch 推理的加速原理:GPU 的矩阵运算存在 计算量-速度非线性关系——大矩阵乘法的计算效率远高于多次小矩阵乘法,因为大矩阵能更好地填满 Tensor Core 和利用显存带宽。
TensorRT + VAE FP16 Fix (Batch=2)
| 配置 | 步长 | 延时(s) | 吞吐(image/s) |
|---|---|---|---|
| Batch 1 | 20 | 2.86 | 0.350 |
| Batch 2 | 20 | 5.55 | 0.360 |
OneDiff + Tiny VAE (Batch=2)
| 配置 | 步长 | 延时(s) | 吞吐(image/s) |
|---|---|---|---|
| Batch 1 | 20 | 3.10 | 0.322 |
| Batch 2 | 20 | 5.60 | 0.357 |
OneDiff + Tiny VAE + CFG 75% (Batch=2)
| 配置 | 步长 | 延时(s) | 吞吐(image/s) |
|---|---|---|---|
| Batch 1 | 20 | 2.90 | 0.344 |
| Batch 2 | 20 | 5.10 | 0.392 |
分析:
- Batch=2 的吞吐提升有限(约 3%~14%),因为 L20 在 Batch=1 时 GPU 利用率已经很高
- Batch 推理的 延时翻倍(两张图同时出),对于在线服务来说,单张图的等待时间更长了
- Batch 的核心限制:同一 Batch 内所有请求的参数必须完全一致(步长、分辨率、模型权重、LoRA 等)
Batch 推理适用场景:高并发且请求参数统一的离线批量生产场景(如电商批量生图)。
2.3 多实例推理实测
多实例方案通过运行多个独立进程,每个进程加载一份模型,利用 GPU 的时间片轮转来服务不同请求。
基于 Triton Inference Server(2 实例)
Baseline: TensorRT + VAE FP16 Fix, 吞吐:0.350 image/s。
我们使用 Triton Inference Server 部署两个 SDXL 实例,模拟不同到达间隔的请求:
场景 1:两个请求同时到达(interval=0s)
延时: 6.25s & 6.25s
Throughput: 0.32 image/s ← 反而低于单实例!
场景 2:两个请求间隔 1s 到达(interval=1s)

延时: 5s & 5s (两个请求间隔 1s 到达)
Throughput: 0.40 image/s(虚假吞吐,因为统计窗口内实际有重叠)
场景 3:模拟多个请求间隔 2s 到达(interval=2s)
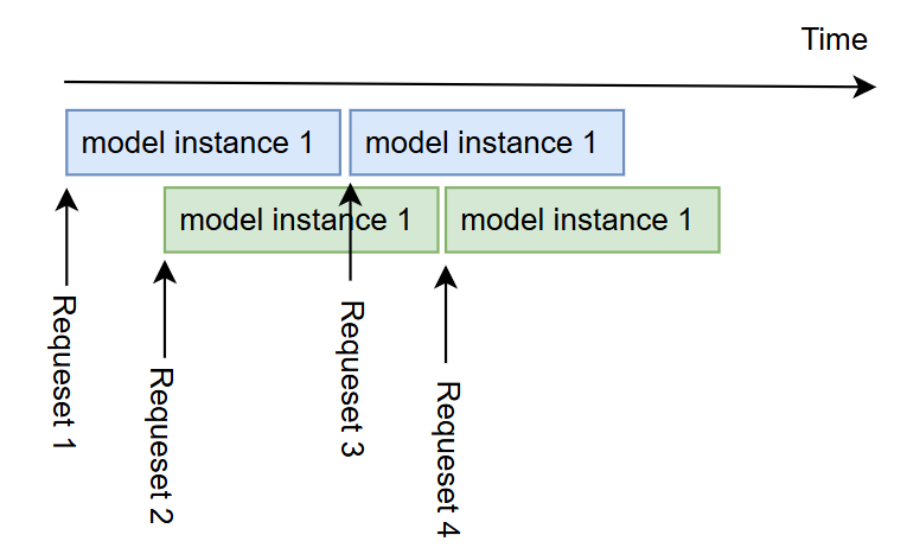
延时: 5.2s & 6.25s & 6.25s & 5s (4个请求,间隔 2s 到达)
Throughput: 0.35 image/s(虚假吞吐,因为统计窗口内实际有重叠)
从这三组结果可以看到一个容易误解的点:多实例并不等价于“更高吞吐”。
- 当请求同时到达(高并发、持续排队)时,两个实例会在 GPU 上发生激烈竞争,真实算子执行被串行化,还会引入额外的切换/抖动开销,所以吞吐反而从 0.35 降到 0.32 image/s。
- 当请求存在间隔(低并发或错峰到达)时,多实例的价值主要体现在降低排队等待(用户感知延时可能更好)。但此时用“短统计窗口”算出来的 Throughput 很容易被请求重叠所“抬高”,出现看似 (0.40) image/s 的虚假吞吐;当模拟多个请求到达情况时,整体吞吐通常仍然接近单实例上限,而不会线性增长。
为什么多实例在高并发下反而更慢?
这是一个非常关键的发现。根本原因在于 GPU 的时间片轮转调度机制:
GPU 时间片调度(无 MPS):
时间 ─────────────────────────────────────────────────────▶
SM: [进程A Kernel] [进程B Kernel] [进程A Kernel] [进程B Kernel] ...
▲ 上下文切换 ▲ 上下文切换 ▲ 上下文切换
问题:
1. 任意时刻只有一个进程占用 GPU → 无真正并行
2. 进程间上下文切换引入额外开销
3. 如果进程 A 未充分利用 SM,空闲资源被浪费(进程 B 无法使用)
在 SDXL 推理场景中,单个模型已经能较好地利用 GPU 资源(利用率 ~98%),多实例在时间片轮转下无法获得额外收益,反而因上下文切换增加了总延时。
多实例适用场景:非高并发场景下,请求到达存在时间间隔时,后到的请求可通过多实例降低等待延时。但在高并发场景下,多实例反而会降低整体吞吐。
2.4 CUDA MPS:突破时间片轮转的限制
MPS 原理
NVIDIA MPS(Multi-Process Service) 正是为了解决上述多实例的资源竞争问题而设计的:
无 MPS(默认时间片轮转):
┌─────────────────────────────────────────┐
│ GPU │
│ 时间片 1: [进程A 独占所有 SM] │
│ 时间片 2: [进程B 独占所有 SM] │
│ → 交替执行,无真正并行 │
└─────────────────────────────────────────┘
有 MPS:
┌─────────────────────────────────────────┐
│ GPU (MPS Server 统一管理) │
│ 同一时刻: [进程A 50% SM] [进程B 50% SM] │
│ → 共享 CUDA Context,真正并行 │
└─────────────────────────────────────────┘
MPS 的核心改进:
- 真正并行:多个进程的 Kernel 在同一时刻执行,共享 SM 资源
- 无上下文切换:所有进程通过同一个 CUDA Context 提交任务,消除切换开销
- 资源隔离:可以通过
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE控制每个进程可用的计算资源比例
MPS 配置与引擎构建
在第一篇 Profiling 中我们发现:SDXL 推理的瓶颈在于 寄存器和共享内存的限制导致 Occupancy 不足。这意味着单个模型无法充分利用所有 SM 资源,为 MPS 多实例并行创造了条件。
关键技巧:在 MPS 模式下,需要 限制 TensorRT 引擎构建时的可用计算资源,使引擎在受限条件下搜索最优策略,以期在多实例共享 GPU 时表现更好。
# Step 1: 设置每个进程可用的计算核心为 50%
export CUDA_MPS_ACTIVE_THREAD_PERCENTAGE=50
# Step 2: 在此环境下构建 TensorRT 引擎
# (引擎会在 50% 资源条件下搜索最优 Kernel 配置)
python build_trt_engine.py
资源限制效果对比: 简单测试下单实例推理时的吞吐变化:
| 限制前: | 限制后: |
|---|---|
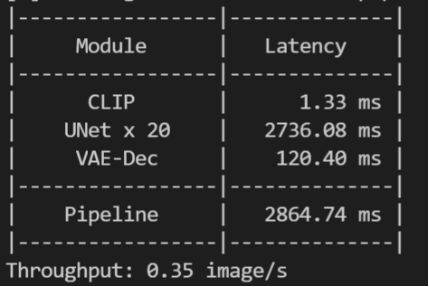 | 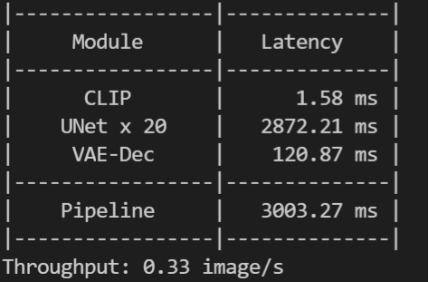 |
可以发现限制资源后, 单实例吞吐由原先的 0.35 下降到 0.33 image/s,说明资源限制生效了。
MPS 实测结果
下面测试多实例 + MPS 的吞吐变化:
# Step 3: 启动 CUDA MPS 控制守护进程
nvidia-cuda-mps-control -d
# Step 4: 启动两个推理实例
python inference_instance_1.py &
python inference_instance_2.py &
| 开启MPS(2 实例) | 不开启MPS(2 实例) |
|---|---|
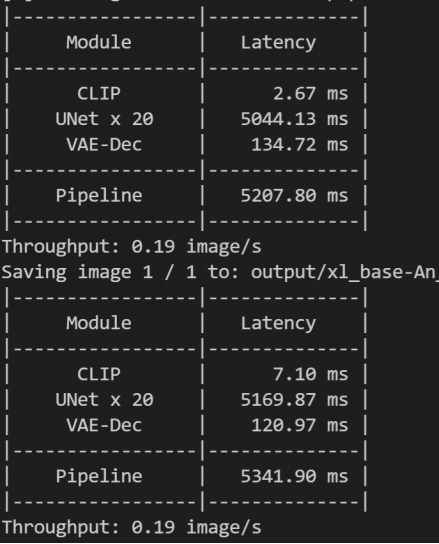 |  |
| 实际Throughput: 0.38 | 实际Throughput: 0.32 |
开启前:两个实例依旧争抢全部 SM,导致 Kernel 执行效率下降 开启MPS后:每个实例可以一定程度上缓解资源竞争,带来资源利用率的提升,吞吐从 0.32 提升到 0.38 image/s,相对无 MPS 双实例提升 18.75%。
2.5 Batch vs 多实例 vs MPS 决策分析
| 配置 | 步长 | 吞吐(image/s) |
|---|---|---|
| TensorRT + VAE FP16 Fix | 20 | 0.35 |
| + Batch 2 | 20 | 0.36 |
| + 多实例 (×2) | 20 | 0.32 |
| + MPS(2 实例) | 20 | 0.38 |
综合以上实验结果,三种策略的适用场景如下:
请求到达模式?
│
├── 高并发(请求几乎同时到达)
│ │
│ ├── 参数一致?
│ │ ├── 是 → Batch 推理(吞吐最高)
│ │ └── 否 → MPS 多实例(支持异构请求)
│ │
│ └── 注意:纯多实例(无 MPS)在高并发下反而降低吞吐
│
└── 低并发(请求有时间间隔)
│
└── 多实例 + MPS
├── 后到请求无需等待前一请求完成
└── 单请求延时不受其他实例影响
3. 最佳工程部署实践
3.1 推荐部署方案
综合所有实验结果,我们给出三套推荐方案:
方案 1:最高吞吐(轻微有损)
OneDiff + Tiny VAE + CFG 75% + Batch 2
├── 吞吐:0.392 image/s
├── 优点:OneDiff 灵活性好,适配 LoRA;吞吐最高
├── 缺点:CFG 可能导致部分 prompt 质量波动
└── 适用:高并发、统一参数的批量生产
方案 2:最高吞吐(精度无损 + 异构请求)
TensorRT + VAE FP16 Fix + 多实例(×2) + MPS
├── 吞吐:0.37 image/s
├── 优点:精度完全无损;两个实例可独立运行不同请求
├── 缺点:TensorRT 灵活性差;MPS 存在故障隔离隐患
└── 适用:低并发异构请求、需要精度保证的场景
方案 3:极致单张延时
TensorRT + Tiny VAE + UNet INT8
├── 单张延时:1.85s
├── 吞吐:0.540 image/s
├── 优点:单张速度最快
├── 缺点:INT8 量化有精度损失;与 LoRA 兼容性差
└── 适用:对延时极度敏感且可接受质量损失的场景
3.2 部署方案对比总览
| 方案 | 延时(s) | 吞吐(image/s) | 质量 | 灵活性 | 风险 |
|---|---|---|---|---|---|
| Baseline (FP16) | 3.9 | 0.256 | 基准 | 最高 | — |
| OneDiff+Tiny+CFG75%+Batch2 | 5.1/张 | 0.392 | 轻微有损 | 高 | CFG 不稳定 |
| TRT+VAE FP16+MPS×2 | 2.86/张 | 0.370 | 无损 | 低 | MPS 故障隔离 |
| TRT+Tiny+INT8 | 1.85/张 | 0.540 | 有损 | 最低 | LoRA 不兼容 |
3.3 生产部署 Checklist
部署前检查清单
═══════════════════════════════════════════════════════
□ 精度:确认使用 FP16(或 BF16),绝不用 FP32
□ VAE:替换为 madebyollin/sdxl-vae-fp16-fix(零成本)
□ 编译:根据场景选择编译框架
□ 固定模型 → TensorRT(提前构建引擎)
□ 动态 LoRA → Stable Fast 或 OneDiff
□ 吞吐策略:
□ 高并发同参数 → Batch 推理
□ 低并发异构 → MPS 多实例
□ MPS 配置(如使用):
□ 启动 MPS 守护进程
□ 设置 CUDA_MPS_ACTIVE_THREAD_PERCENTAGE
□ 在受限资源下构建 TensorRT 引擎
□ 监控:
□ GPU 利用率 / 显存占用 / 推理延时
□ MPS 故障隔离监控
□ 质量验证:
□ 使用业务 prompt 集验证优化后图片质量
□ 特别关注 CFG 优化的稳定性
4. 系列总结
三篇核心脉络回顾
第一篇:知其然 —— 模型剖析与 Profiling
├── SDXL Pipeline 三阶段解构(TextEnc → UNet → VAE)
├── UNet 占 90%+ 推理时间,Attention 访存密集
├── Nsight Systems 宏观时间线 + Nsight Compute 微观 Kernel 分析
└── 结论:GPU 利用率已高,优化重点在"每个 op 更快"和"减少 op 数量"
第二篇:知其所以然 —— 单项优化实践
├── 精度优化:FP16 带来 3× 加速(收益最大的单项优化)
├── 编译优化:torch.compile / StableFast / OneDiff / TensorRT (1.1~1.25×)
├── 组件优化:VAE Fix / TinyVAE / CFG / DeepCache / 蒸馏
└── 结论:每种优化都有 trade-off,无银弹
第三篇:学以致用 —— 混合优化与工程部署
├── 混合组合:TRT+VAE FP16 Fix 无损最佳(1.41×);TRT+INT8 极速(2.1×)
├── 吞吐三策略:Batch(高并发) / 多实例(低并发) / MPS(真并行)
├── MPS 核心发现:解决多实例资源竞争,吞吐提升 19%
└── 三套推荐部署方案 + 生产 Checklist
最终性能达成
| 指标 | 优化前 (FP32) | 优化后(最佳) | 提升倍数 |
|---|---|---|---|
| 单张延时 | 16.3s (30步) | 1.85s (20步, TRT+INT8) | 8.8× |
| 单卡吞吐 | ~0.06 image/s | 0.392 image/s (OneDiff+Batch) | 6.5× |
| 显存占用 | 18.08 GB | 5.76 GB (Batch Process) | 3.1× |
未来优化方向
- DiT 架构:Stable Diffusion 3 / FLUX 等新一代模型采用 DiT(Diffusion Transformer)架构,优化思路将有所不同
- Speculative Decoding for Diffusion:借鉴 LLM 的投机解码思想,用小模型预测多步再用大模型验证
- 动态量化:运行时自适应量化精度,在质量和速度间动态平衡
- 多 GPU 并行:Tensor Parallel / Pipeline Parallel 在多卡场景下的应用
参考资料: